The adjoint method provides a new way of thinking about and deriving formulas for certain computation process. In this article, we will present the basic ideas of the adjoint method and, as a concrete example, demonstrate its consequences in back-propagation of the dominant eigen-decomposition and its relation with the traditional approach.
$\renewcommand{\vec}[1]{\mathbf{#1}}$
Basic ideas of the adjoint method
Consider a simple computation process, in which the setting is as follows. Let $\vec{p} = (p_1,\cdots, p_P)$ be a $P$-dimensional input vector of parameters, and the output $\vec{x} = (x_1, \cdots, x_M)^T$ is a $M$-dimensional (column) vector. They are related by $M$ equations of the form $f_i(\vec{x}, \vec{p}) = 0$, where $i$ ranges from $1$ to $M$.
What we need is the back-propagation of this process, in which the adjoint $\overline{\vec{p}} \equiv \frac{\partial \mathcal{L}}{\partial \vec{p}}$ of input is expressed as a function of the adjoint $\overline{\vec{x}} \equiv \frac{\partial \mathcal{L}}{\partial \vec{x}}$ of output. We have
where the $M$-dimensional column vector $\frac{\partial \vec{x}}{\partial p_\mu}$ is determined by
Or, we can express this in a more compact form as follows:
where
Assuming the $M \times M$ matrix $\frac{\partial f}{\partial \vec{x}}$ is invertible, one can solve for $\frac{\partial \vec{x}}{\partial p_\mu}$ from Eq. $\eqref{eq: partialxpartialp}$, then substitute it back into Eq. $\eqref{eq: adjointp}$ to get the final result:
where the column vector $\boldsymbol{\lambda}$ is determined by
Example: dominant eigen-decomposition
As a concrete example of the adjoint method, consider the dominant eigen-decomposition process, in which a certain eigenvalue $\alpha$ and corresponding eigenvector $\vec{x}$ of $A$ is returned (assuming the eigenvalue is non-degenerate), where $A = A(\vec{p})$ is a $N \times N$ real symmetric matrix depending on the parameter $\vec{p}$.
Note that in the current case, the output can be effectively treated as a vector of dimension $N + 1$. The correspondence with the general notations in the last section is thus as follows:
The $N + 1$ equations $f_i(\vec{x}, \alpha, \vec{p}) = 0$ are given by
where the subscript $i$ denotes the $i$th column of the matrix $A - \alpha I$, and the extra equation $f_0(\vec{x}, \alpha, \vec{p}) = 0$ imposes the normalization constraint. Using Eq. $\eqref{eq: fs}$, one can easily obtain that
In correspondence with Eq. $\eqref{eq: lambda in general case}$ in the general case, the matrix equation satisfied by $\boldsymbol{\lambda}$ and $k$ thus yields
One can solve for $k$ by multiplying both sides of the first equation by $\vec{x}^T$, and obtain
Substituting it back to Eq. $\eqref{eq: matrix equation of lambda and k}$, one can obtain the unique solution for $\boldsymbol{\lambda}$ as follows:
The vector $\boldsymbol{\lambda}_0$ in the equation above can be solved by Conjugate Gradient (CG) method.
Finally, note that in the current case,
In correspondence with Eq. $\eqref{eq: adjointp in general case}$, one thus obtains
Or, one can “strip” the parameter $\vec{p}$ out of the function primitive and obtain the expression of $\overline{A}$ by taking account of the fact that $\overline{p_\mu} = \textrm{Tr}\left(\overline{A}^T \frac{\partial A}{\partial p_\mu}\right)$. The final result is
Fairly simple.
Relation with the derivation based on full eigen-decomposition
Now, let’s try to figure out the relation of the above approach based on adjoint method with that of the full eigen-decomposition process. The only difference is that compared with the full diagonalization formulation, the adjoint method presented above only needs one specific eigenvalue(usually the smallest or the largest one) and corresponding eigenvectors. Nevertheless, we can “wrap” the process of full diagonalization within the dominant eigen-decomposition and utilize the results of the former formulation in the latter, as demonstrated in the figure below.
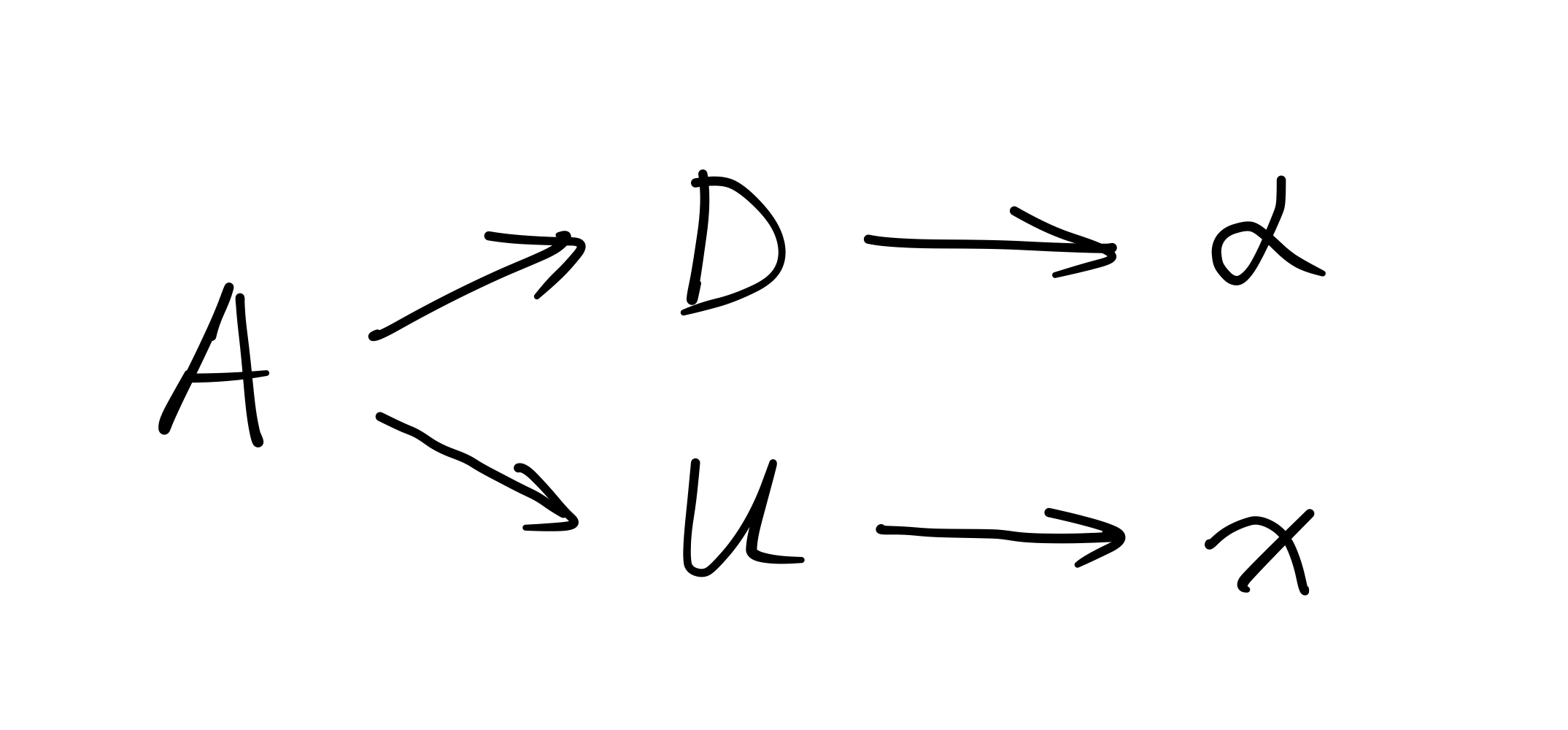
For clarity and without loss of generality, let $\alpha$ and $\vec{x}$ be the “first” eigenvalue and corresponding eigenvector of the matrix $A$. That is, we have $U^T A U = D$, where
Recall that the full eigen-decomposition gives the following backward formula of $\overline{A}$ in terms of $\overline{D}$ and $\overline{U}$:
where $F$ is an anti-symmetric matrix with off-diagonal elements $F_{ij} = (\alpha_j - \alpha_i)^{-1}$. For more details, see the references in the last section. On the other hand, the dominant eigen-decomposition described above yields the following relations between $\overline{D}, \overline{U}$ and $\overline{\alpha}, \overline{\vec{x}}$:
Then one can obtain through simple algebraic manipulation that
where we have introduced the quantities $c_i = \frac{1}{\alpha_i - \alpha} \vec{x}_i^T \overline{\vec{x}}, \quad \forall i = 2, \cdots, N$. Substituting this equation back into $\eqref{eq: full diagonalization AD}$, we have
This formula looks very similar to the result $\eqref{result: dominant diagonalization}$ obtained from the adjoint method. Actually they are identically the same. This can be seen by expanding the vector $\boldsymbol{\lambda}_0$ characterized in Eq. $\eqref{lambda0}$ in the complete basis $(\vec{x}, \vec{x}_2, \cdots, \vec{x}_N)$. One can easily see that the quantities $c_i$ defined above are exactly the linear combination coefficients of $\boldsymbol{\lambda}_0$ in this basis. In other words, we have
Plugging this result back into $\eqref{result: full diagonalization}$ clearly reproduces the earlier result $\eqref{result: dominant diagonalization}$.
Remarks
The observation above clarifies the equivalence of the two formulations of deriving the back-propagation of the dominant eigen-decomposition process. The fact that the final result is identically the same is not surprising, but the “native” representations of the result are indeed different from a practical point of view. In the formulation based on adjoint method, one only makes use of the “dominant” eigenvalue and eigenvector instead of the full spectrum, thus allowing for the construction of a valid dominant eigensolver function primitive in the framework of automatic differentiation. In a typical implementation, the forward pass can be accomplished by Lanczos or other dominant diagonalization algorithms, while the backward pass can be implemented by solving the linear system $\eqref{lambda0}$ using Conjugate Gradient method. In the case of large matrix dimension, this approach is clearly more efficient.
References
The presentation of general ideas of adjoint method and its application in dominant eigen-decomposition is largely based on this notes:
There are some good notes on automatic differentiation of basic matrix operations, including the full eigen-decomposition process. For example: